
Architettura RDNA4
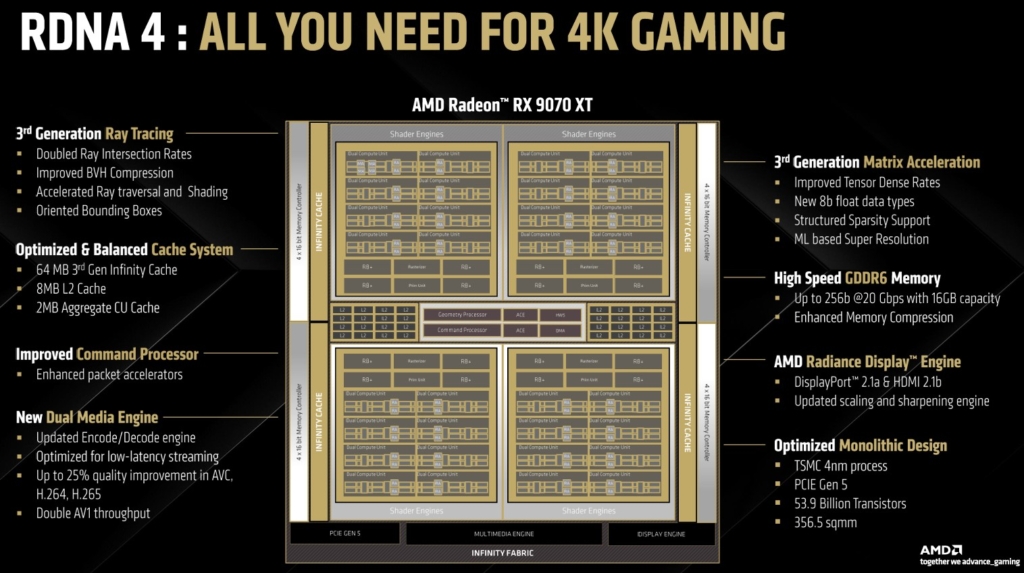
Navi 48, questo il nome in codice della nuova GPU AMD, che sarà affiancata successivamente da Navi 44 per la serie 9060, rappresenta lo sforzo di Radeon Group per creare un prodotto non troppo grosso, misura 357 mm2, e migliorare ogni aspetto insito nei suoi CU oltre che modernizzare l’impianto Matrix in vista del supporto dell’upscaling ML esclusivo (per ora) FSR4.
Insomma, non aumentano il numero di unità di calcolo, che sono un massimo di 64 per 4096 stream processors, contro le 96 CU della ex top di gamma AMD RX 7900 XTX, ma l’efficienza delle stesse le permettono di competere molto da vicino grazie all’ottimizzazione intra chip.
In verità, almeno all’inizio della progettazione di RDNA4, pare esistesse una versione MCM in grado di integrare ben 17 chip differenti, ma data la complessità di ottimizzazione e di sviluppo si è pensato di puntare nuovamente, crediamo con raziocinio, sul monolitico.
In verità se si prende a riferimento il numero di transistor, in questo caso 53,9 miliardi, abbiamo volumi, grazie al processo produttivo a 4 nm N4C di TSMC, decisamente simili a quelli di RX 7900 XTX che però ha una dimensione di ben 529 mm2 considerando i vari chip, il che ci indica una estetica della realizzazione della GPU stessa decisamente più raffinata.
Certo qualcuno potrebbe obiettare che non vi sia il chip di stacco, questo è vero ma vedendo anche la concorrenza e il target, oltre l’esigenza di riconquistare quote di mercato, nuovamente ritengo la decisione di AMD corretta.
Anche per il comparto memoria, da 16 GB GDDR6 a 20 Gbps su bus a 256 bit si è preferita l’ottimizzazione dei carichi tramite una Infinity Cache rimodellata a 64 MB e un nuovo algoritmo di gestione che introduce l’ Out-of-Order Memory Queuing.
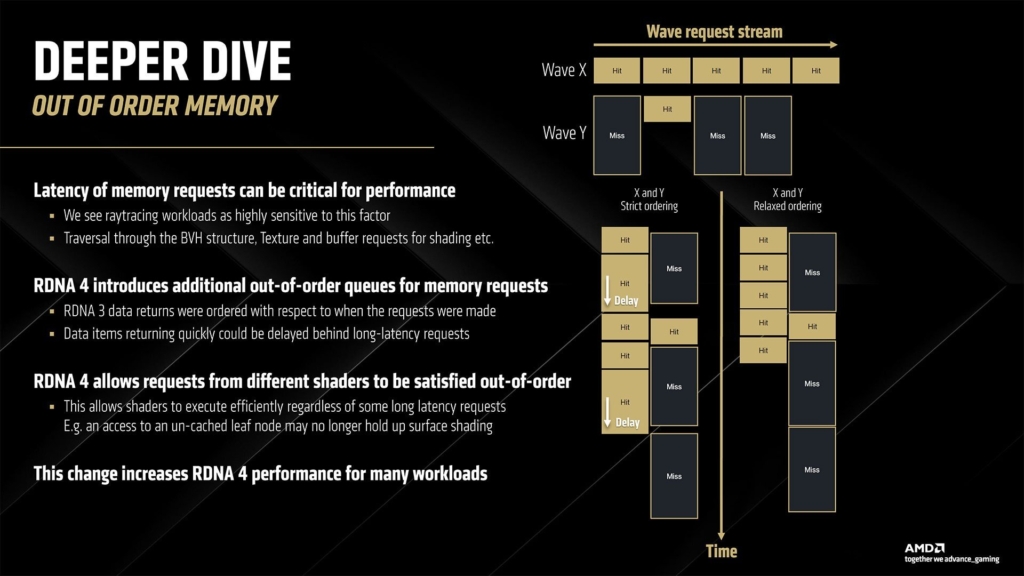
Quest’ultimo è una ottimizzazione necessaria per fornire più flessibilità di calcolo soprattutto in ambito ML e Ray Tracing, istanze che possono patire il tradizionale ordine di esecuzione: con questa nuova modalità di accesso alla memoria si possono evitare, con una maggiore flessibilità, colli di bottiglia nelle varie wave e passare direttamente ad un accesso “prioritario” non patendo attese inutili.
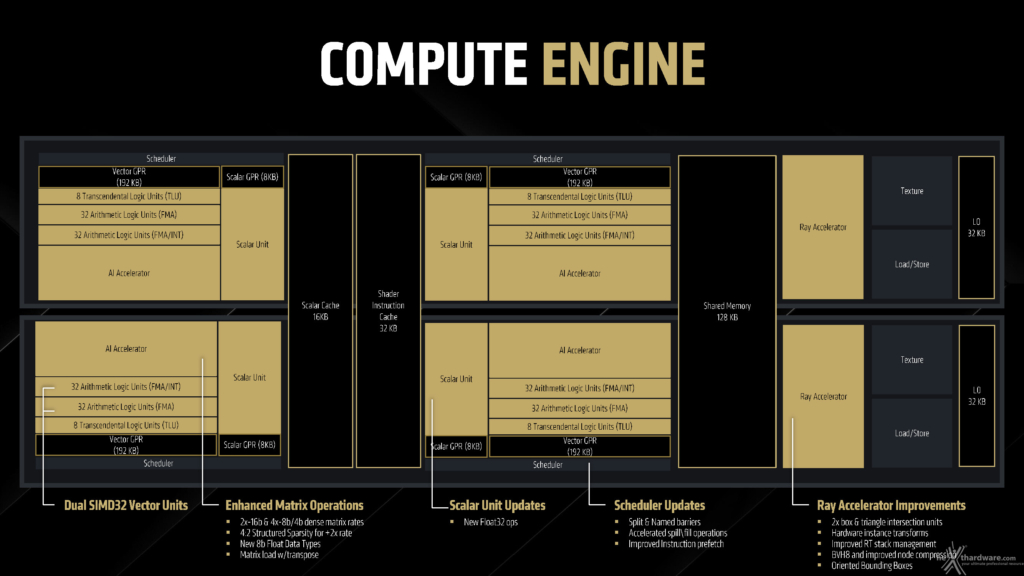
Il cuore però di Navi 48 sono le nuove DUAL CU unit, e dove il lavoro di AMD è stato più incisivo, in grado di migliorarne l’efficienza di un buon 40%, fattore di cui beneficeranno tutta una serie di prodotti laterali come APU o device Handheld in futuro.
Trovo onestamente quasi commovente la serie di novità introdotte: partiamo dalle unità di calcolo in configurazione DUAL SIMD con capacità float/int in una e solo Float nell’altra slegandosi quindi anche dai calcoli Matrix, molti ricorderanno un approccio similare di Nvidia con serie 3000, fu una ottimizzazione interessante e convincente e ora la ritroviamo anche in Navi già da RDNA3, affiancante ad esse 8 TLU (Transcendental Logic Units) con cache da 192 KB per i nuovi sheduler (2) e capacità rinnovate di prefetch , una unità scalare con i propri registri da 8 KB con possibilità di operazioni Float32, un AI Accelerator di nuova generazione che vedremo successivamente e, ovviamente, le rinnovate RA (Ray Accelerator) con capacità 2X rispetto a RDNA3 il tutto tenuto insieme da altri 128 KB di memoria condivisa ogni due CU.
Se tutto questo è stato pensato per rendere i calcoli più efficienti e fare con 64 CU quello che prima si faceva con 96, in ambito AI e Ray Tracing si è voluto fare un enorme passo in avanti e probabilmente sono stati pensati come gli ambiti d’attacco nel progetto Radeon.

Partendo dalle unità AI troviamo capacità rinnovate prese a piene mani dalle soluzioni professionali GPU di AMD: quindi maggior supporto di formati, primo fra tutti FP8 e e tecniche di Sparsity come quelle introdotte nei Tensor cores delle architetture AMPERE qualche anno fa.
Il tutto cosa comporta, in termini matematici un raddoppio delle performance in caso di calcoli dense FP16, 4 volte in sparsity 4:2, fino a 8X in caso di INT4 e 8, non valutabile in FP8 non essendo supportato da RDNA3, ma, soprattutto, apre all’utilizzo di algoritmi hardware di upscaling quali FSR4, teoricamente possibili anche per l’architettura precedente seppur con minore pregio (ma questo lo vedremo).
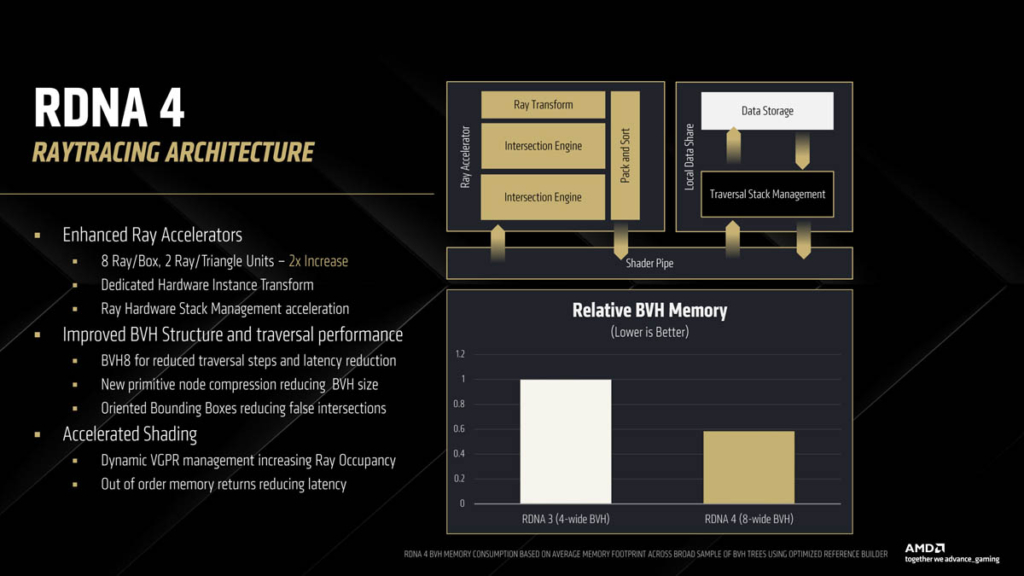
Il Ray Tracing, grande argomento di dibattito, con nuovi RA a supporto.
L’approccio di AMD è sempre stato per una soluzione ibrida che coniugasse tecniche di rasterizzazione classica combinate a qualche introduzione di Ray Tracing dove servisse, in particolare in ombre e ambient occlusion in abbinamento all’ottimo CACAO, o Global Illumination.
Con RDNA 3 le performance delle basi lasciate da RDNA2 hanno visto un upgrade medio, a parità di RA del 20% effettivo, con ottimizzazioni in grado di abbattere le iterazioni per traversal ray grazie al Early Subtree Culling in termini davvero importanti e al contempo aumentare la capacità effettiva di circa un 50%, limitata da altri fattori quali la fase di denoising.
Arrivando a RDNA 4, ormai direi che non si scherza più. La novità più importante è la fase di Denoising effettuata grazie a Matrix Engine, il che da spazio per un importante upgrade dei risultati ottenibili e ora solamente anticipati: raddoppiano le capacità computazionali, con 8 ray/box e 2 ray/triangle per clock, una nuova tecnica chiamata oriented bounding boxes che non fa altro che fornire un asse Z alla figura geometrica per orientare meglio lo spazio di testing e ridurre le iterazioni e latenza per un guadagno di performance ulteriore del 10%, oltre che avere un impatto sulla memoria dei calcoli BVH praticamente dimezzato grazie alla compressione dei nodi primitivi.

Sommando tutti i fattori, le capacità pure in RT della nuova architettura dovrebbero essere circa il 120-130% meglio rispetto a RDNA 3 in ambiente di test senza altri fattori in gioco, quali banda memoria, engine, rasterizzazione, il che da il polso chiaro dove si sia investito maggiormente.
A livello di elaborazione visiva abbiamo poi il nuovo Radiance Display Engine 2 che introduce la seconda versione di una delle prime suite presenti in Open GPU fin da RX 5700 XT, CAS o RIS che sia, meglio conosciuto come image sharpering.
Oltre a questo segnalo il supporto a una versione meno dispendiosa in termini di watt di Freesync in presenza di multi monitor, più un fix che un upgrade e le nuove specifiche VESA DisplayPort 2.1a e HDMI 2.1b.

Infine aggiornati anche i due engine di codifica e decodifica con un 25% di performance in più in H264, 11% HEVEC, migliorie del 30% nelle codifiche a 720P, supporto ai B frames nella codifica e decodifica AV1 (con soli vettori di movimento) e riduzione dell’incidenza sulla memoria.

Insomma ogni aspetto dell’offerta Radeon è stato ottimizzato o migliorato.
Sempre professionali! top
Grazie Andrea
Quindi con questa scheda vogliono prendersi quale fetta di mercato? Perché credo che abbiamo deciso di ignorare la guerra con nvidia con questa scheda.
Al contrario, puntano alla fetta più ghiotta, a quelli da RTX 5070 ti a un prezzo più competitivo.
Bellissima analisi, soprattutto il confronto con le precedenti architetture.
Queste schede rullano veramente bene, anche in undervolt danno belle soddisfazioni.